Movie-Recommendation-System
Movie Recommendation System

The Problem
An online cinema platform was losing users — not because its catalogue was too small, but because users couldn’t find films they’d actually enjoy. A homepage that looks the same for every visitor isn’t a product; it’s a library with no librarian.
The client needed a recommendation engine that could surface the right film for each individual user, based on their viewing history — something closer to what Netflix or Amazon Prime deliver, built from the ground up.
The engineering challenge was real. The dataset had enormous variability: some users had rated nearly 13,000 movies, while others had rated just one. Some films had over 30,000 ratings; others had a single vote. That kind of imbalance breaks naive models immediately — a problem known as the cold start problem, where the system has too little signal to make meaningful predictions for most users.
What I Built
A hybrid movie recommendation system that combines two approaches to give personalised, user-specific suggestions:
Content-based filtering — recommends films similar to ones a user has already enjoyed, using movie metadata (genre, description, cast) and cosine similarity to measure how closely films relate to each other.
Collaborative filtering — identifies users with similar taste profiles and recommends films those users liked. Built using matrix factorisation algorithms that learn latent patterns in rating behaviour across the entire user base.
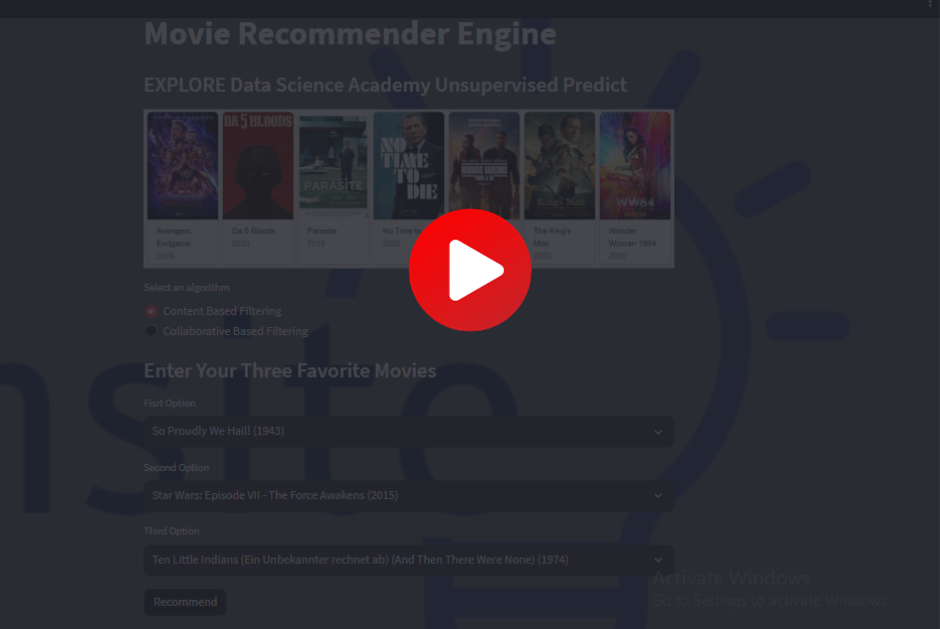
The final application takes a user’s last three rated movies and generates a ranked list of recommendations. It was deployed as a live web app on AWS, accessible without any technical knowledge.
My Contribution
Exploratory Analysis & the Cold Start Problem
Before touching a model, I ran a thorough exploratory analysis to understand the shape of the data — rating distributions, user activity patterns, and which movies had enough signal to be reliably recommended.
The key finding was striking: the top 20 most-rated movies had tens of thousands of ratings each, while the majority of films had almost none. The same skew appeared for users.
| Distribution | Range |
|---|---|
| Movie ratings per film | 1 → 32,831 |
| Movies rated per user | 1 → 12,952 |
A model trained on this raw data would be dominated by a handful of popular films and active users — useless for personalised recommendations. My solution was to apply a rating threshold of 500: filtering out users and movies below this minimum before training. This narrowed the dataset to interactions with enough signal to be meaningful, without discarding the diversity needed for varied recommendations.
Content-Based Filtering
I built the content-based pipeline from scratch: cleaning and normalising movie metadata through tokenisation, stopword removal, lemmatisation, and TF-IDF vectorisation. I then computed cosine similarity scores between all film pairs in the corpus, which powers the “if you liked X, you’ll like Y” logic.
Collaborative Filtering
I trained and benchmarked four matrix factorisation algorithms using the Surprise library:
| Algorithm | Description |
|---|---|
| SVD | Singular Value Decomposition — the industry standard for collaborative filtering |
| SVD++ | SVD extended with implicit feedback signals |
| PMF | Probabilistic Matrix Factorisation |
| NMF | Non-negative Matrix Factorisation |
All models were evaluated on F1-score. SVD delivered the best performance and was selected for the final application.
Deployment
The final hybrid model was packaged into a Streamlit application and deployed on AWS (EC2 + S3). The app takes a user’s recent viewing history as input and returns a personalised set of recommendations — no technical setup required for the end user.
Demo
Tech Stack
| Area | Tools |
|---|---|
| Language | Python |
| Data Processing | Pandas, NumPy |
| NLP & Feature Engineering | NLTK, Scikit-learn (TF-IDF, cosine similarity) |
| Collaborative Filtering | Surprise (SVD, SVD++, PMF, NMF) |
| Evaluation | F1-Score |
| Deployment | Streamlit, AWS EC2, S3 |
| Project Management | Trello |
| Version Control | GitHub |
Key Insight: Why the Cold Start Solution Mattered
The 500-rating threshold wasn’t an arbitrary cut. It was a deliberate engineering decision that balanced two competing goals: having enough data per user and movie to train reliable predictions, while keeping enough variety in the dataset to avoid recommending the same 20 blockbusters to everyone.
Below that threshold, the collaborative filter was essentially guessing. Above it, it had enough signal to detect genuine taste patterns. Getting that threshold right required iterating on the EDA — not just applying a rule of thumb.
What I’d Do Differently
- Deep learning recommenders — neural collaborative filtering (NCF) or two-tower models would likely outperform SVD, especially for capturing non-linear preference patterns that matrix factorisation misses.
- Implicit feedback — most users don’t rate films; they just watch them. Incorporating implicit signals (watch time, rewatches, abandonments) would build a far richer picture of user preference than explicit ratings alone.
- Real-time personalisation — the current system generates recommendations at request time from a static model. An online learning setup that updates as users interact would keep recommendations fresh.
- Diversity constraints — pure performance optimisation tends to produce recommendations that cluster around a user’s known preferences. Adding a diversity penalty would help surface unexpected films a user might genuinely love.
Team
This was a collaborative project. Credit to the full team:
- Toluwatise Onadipe
- Grace Quinn
- Kennedy Chege
- Chidinma Madukife
Let’s Talk
If you’re working on a recommendation system, NLP pipeline, or any ML project that needs to go from research to deployment — get in touch.